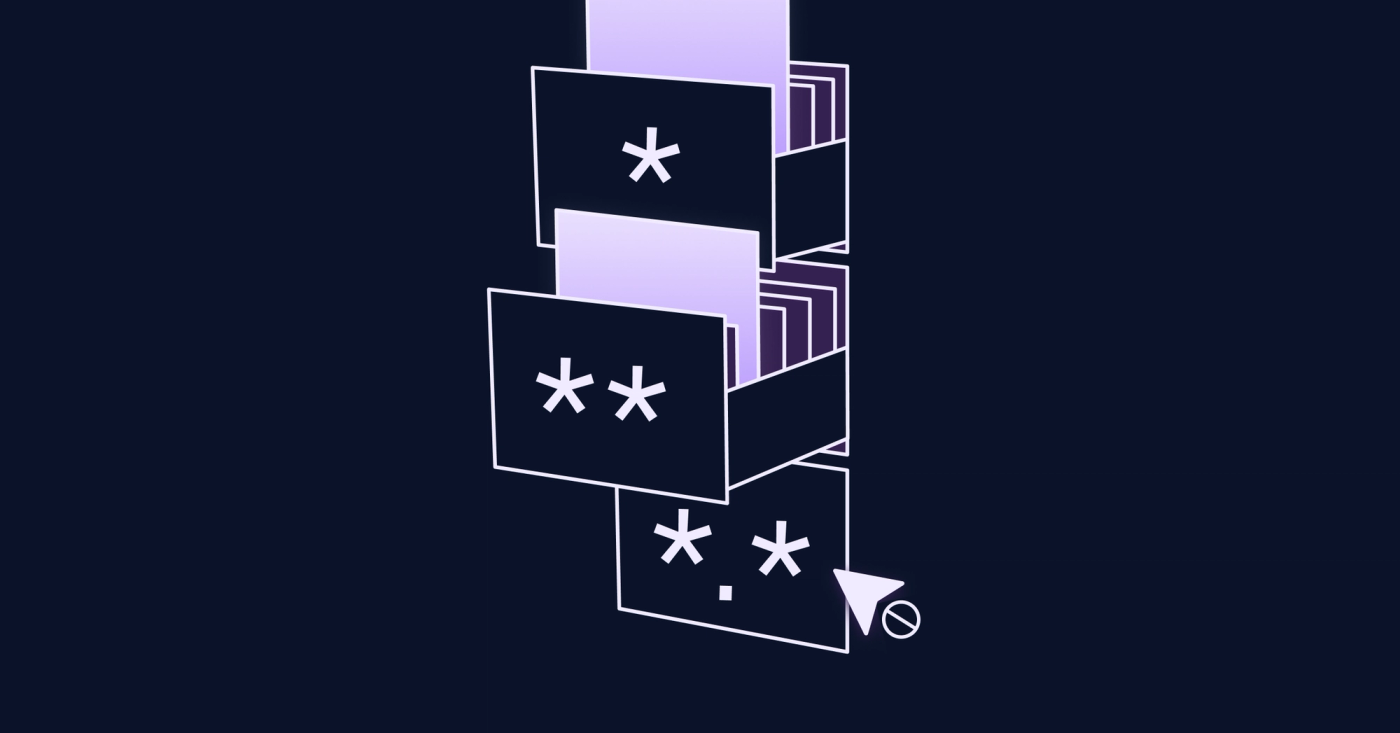
The Sanity Content Lake comes with a powerful feature for documents IDs that I didn’t know about. As this feature was the root cause of some unexpected (to me) functionality I want to write about it here. This feature is described in detail on the official documentation under the title Paths . Although I vaguely remember reading through this page at some point it did not save me from an unnecessary and long debug session.
So here’s a lesson on the powerful functionality hidden inside Sanity’s document IDs.
tl;dr
When prefixing a document id with a string + ., e.g. settings.tokens it will become a namespaced document and will be hidden to unauthorized clients – even in public datasets.
What are namespaced IDs Link to this headline
Every document in Sanity has an _id attribute by which it is identified. The format of this ID can be a string with a maximum length of 128 characters. The following characters can be used a-zA-Z0-9._-. Some more restrictions apply, more information can be found on the official Sanity documentation .
When using the . character in the _id a “path” is created. This path can be used to organize and query documents in a hierarchical way.
Querying namespaced IDs Link to this headline
The query language GROQ comes with a function to filter documents by their path. The following query will output all documents whose _id attribute starts with settings.
*[_id in path(settings.**)]
// example output:
// […] 4 items
// { _id: "settings.handles.socialmedia", … },
// { _id: "settings.tokens", … },
// { _id: "settings.tokens.socialmedia", … },
// { _id: "settings.tokens.hosting", … },The asterisk * works similar to glob patterns and can be used as a wildcard for path segments.
*[_id in path(settings.*)]
// example output:
// […] 1 item
// { _id: "settings.tokens", … },This seems to be working only for the end of the path, though. path(settings.*.socialmedia) won’t work.
Drafts as a special case of predefined namespaced IDs Link to this headline
When editing a document in Sanity studio it will create a copy of the document as a “draft”. All drafts are namespaced by the drafts path, e.g. the draft of a document with the ID test would be saved under the ID drafts.test.
For queries run using the raw perspective filtering drafts using the path() function works:
// in `raw` mode
*[_id in path(draft.**)]
// will return all documents in draft stateThis changes however when switching into one of the other perspective modes.
// in `previewDrafts` or `published` mode
*[_id in path("drafts.**")]
// [] 0 itemsThe (almost) hidden feature Link to this headline
There’s another functionality for IDs with paths: all documents with an ID including a . are hidden by default. That means these documents won’t appear in any query sent to the Content Lake API from an unauthorized client. This is true for public datasets, too.
None of the queries above will return any settings.** document, when they’re being send from a client that is configured without a valid token.
Of course this functionality is shared with draft documents. Even before the introduction of perspectives, these weren’t available in public queries. I just never realized that this is true for all documents using “namespaced IDs”.
Internal Content Lake Functionality Link to this headline
The content lake uses namespaced IDs to manage internal information. The documentation mentions that IDs prefixed with versions. could interfere with platform functionality.
Running the following query will reveal information on the roles defined in the dataset:
*[_id in path(_.**)]
// […] 10 items
// { "_id": "_.groups.administrator", "_type": "system.group", … },
// { "_id": "_.groups.create-session", "_type": "system.group", … },
// { "_id": "_.groups.public", _type": "system.group", … },
// …
Escape Hatch Link to this headline
These roles also include a grants.filter array that holds the filters used to expose certain paths to authenticated roles like administrator or editor:
*[
_id in path("_.**") &&
count(grants[].filter) > 0
] {
_id,
"filter": grants[].filter
}
// […] 4 items
// {
// "_id": "_.groups.administrator",
// "filter": [
// "_id in path(\\\\"**\\\\")",
// "(_id in path(\\\\"**\\\\")) && _id in path(\\\\"drafts.**\\\\")"
// ]
// },
// {
// "_id": "_.groups.public",
// "filter": [
// "_id in path(\\\\"*\\\\")"
// ]
// },
// {
// "_id": "_.groups.sanity.editor",
// "filter": [
// "_id in path(\\\\"**\\\\")",
// "(_id in path(\\\\"**\\\\")) && _id in path(\\\\"drafts.**\\\\")"
// ]
// },
// {
// "_id": "_.groups.sanity.viewer",
// "filter": [
// "_id in path(\\\\"**\\\\")",
// "(_id in path(\\\\"**\\\\")) && _id in path(\\\\"drafts.**\\\\")"
// ]
// }
On plans that “allow custom access controls” these filters can apparently be changed. As only enterprise plans allow for custom access controls (in the section “Security & Compliance”) I never had the chance to test this.
If you’re not on an enterprise plan you cannot easily expose namespaced IDs. Ways to query documents with namespaced IDs on public datasets are:
- configure a Sanity client with an access token
- if you don’t want to expose the access token to a (browser) client, you can add an API route to your setup to fetch the documents using a token
As far as I know there’s no other way to get access to these documents if they use a an id with a path.
Pitfalls Link to this headline
The way I found out about paths in IDs hiding documents from unauthorized clients was an annoying Friday evening debugging session. I was migrating a Sanity setup using the document-internationalization plugin in version 1 to its newest version >3.
I encountered two hard to debug issues in quick succession. First I was using content migrations in their new form, as I find these very nice to work with. When creating the metadata documents similar to how its done in the official documentation I omitted the _id attribute. The _id does not seem to be required when using the create function of the Content Lake API. I was testing my migration in small steps and resorted to using the createIfNotExists function of the API which does in fact require a document ID to be present (which makes total sense).
My migration included patches as well as new documents to be created and at first I couldn’t make sense where the error came from (although its message is fairly obvious).
# HTTPError: mutationError: Mutation failed: Missing document IDOnce I figured that out I added an ID to the translation documents:
const metadata = createIfNotExists({
_id: `translation.${document._id}`,
_type: "translation.metadata",
translations: [
{
_key: document[LANGUAGE_FIELD],
value: {
_type: "reference",
_ref: document._id.replace("drafts.", ""),
...weakRefs,
},
},
...refs,
],
});
The migration ran flawlessly now. The local environment was using a token and worked fine as well. At first sight the preview deployment appeared to be working, too! But when I wanted to switch the website’s language that I was working on things started to fall apart. The alternate languages for each page weren’t loading because the unauthorized client could not access the “hidden” translation.* documents.
This is definitely something to be aware of when using namespaced IDs. I won’t forget that this feature exists after a debugging session that took longer than I’d like to admit.
Applications for namespaced IDs Link to this headline
In our setups we sometimes have plugins configured for the Sanity studio dashboard. These plugins often connect to external services to fetch some data and persist it in the Sanity dataset for easy access from the frontend. Or they trigger functionality by calling a webhook. Both of these use tokens for authentication.
These tokens can be stored in the Content Lake using a namespaced ID like settings.tokens. This way they will be accessible to the dashboard plugin through the user authenticated client, but not leak to the public. Which is really handy.
Let me know if you know of any other use cases! I am eager to learn more about this functionality.



'/%3e%3cpath%20d='M62.0348%20162.889L123.416%20162.889'%20stroke='white'%20stroke-width='4.76'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M62.0348%20170.889L123.416%20170.889'%20stroke='white'%20stroke-width='4.76'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M62.0348%20178.889L123.416%20178.889'%20stroke='white'%20stroke-width='4.76'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_3690_24257'%20x1='93.4124'%20y1='10'%20x2='93.4124'%20y2='156.912'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2369FD90'/%3e%3cstop%20offset='1'%20stop-color='%23DFFAED'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
'%3e%3ccircle%20cx='93.2117'%20cy='93.2115'%20r='79.373'%20fill='white'/%3e%3ccircle%20cx='92.9737'%20cy='93.2115'%20r='60.571'%20fill='%230B1329'/%3e%3cmask%20id='path-3-inside-1_3690_24255'%20fill='white'%3e%3cpath%20d='M93.2117%20172.584C73.9198%20172.584%2055.2883%20165.558%2040.8004%20152.82C26.3125%20140.081%2016.9599%20122.502%2014.4913%20103.368C12.0226%2084.2351%2016.6068%2064.8577%2027.3869%2048.8588C38.1669%2032.8598%2054.4049%2021.3347%2073.0649%2016.4379L77.9002%2034.8636C63.7185%2038.5851%2051.3777%2047.3442%2043.1848%2059.5034C34.992%2071.6626%2031.508%2086.3895%2033.3842%20100.931C35.2603%20115.472%2042.3683%20128.832%2053.3791%20138.514C64.39%20148.195%2078.5499%20153.535%2093.2117%20153.535L93.2117%20172.584Z'/%3e%3c/mask%3e%3cpath%20d='M93.2117%20172.584C73.9198%20172.584%2055.2883%20165.558%2040.8004%20152.82C26.3125%20140.081%2016.9599%20122.502%2014.4913%20103.368C12.0226%2084.2351%2016.6068%2064.8577%2027.3869%2048.8588C38.1669%2032.8598%2054.4049%2021.3347%2073.0649%2016.4379L77.9002%2034.8636C63.7185%2038.5851%2051.3777%2047.3442%2043.1848%2059.5034C34.992%2071.6626%2031.508%2086.3895%2033.3842%20100.931C35.2603%20115.472%2042.3683%20128.832%2053.3791%20138.514C64.39%20148.195%2078.5499%20153.535%2093.2117%20153.535L93.2117%20172.584Z'%20fill='%230B1329'%20stroke='white'%20stroke-width='9.52'%20mask='url(%23path-3-inside-1_3690_24255)'/%3e%3cmask%20id='path-4-inside-2_3690_24255'%20fill='white'%3e%3cpath%20d='M72.6684%2016.5432C83.5818%2013.619%2094.9937%2013.0584%20106.141%2014.8988C117.289%2016.7393%20127.915%2020.9384%20137.309%2027.2154C146.703%2033.4925%20154.649%2041.7027%20160.615%2051.2973C166.582%2060.8919%20170.431%2071.6497%20171.906%2082.8514C173.38%2094.0531%20172.447%20105.441%20169.167%20116.252C165.887%20127.064%20160.337%20137.051%20152.887%20145.546C145.438%20154.04%20136.261%20160.847%20125.969%20165.51C115.678%20170.173%20104.51%20172.585%2093.2117%20172.585L93.2117%20153.535C101.798%20153.535%20110.286%20151.702%20118.108%20148.158C125.929%20144.614%20132.904%20139.442%20138.565%20132.986C144.227%20126.53%20148.445%20118.94%20150.938%20110.723C153.43%20102.506%20154.14%2093.8512%20153.019%2085.3379C151.898%2076.8246%20148.973%2068.6487%20144.439%2061.3568C139.904%2054.0649%20133.865%2047.8251%20126.726%2043.0545C119.586%2038.284%20111.51%2035.0926%20103.038%2033.6939C94.566%2032.2952%2085.893%2032.7213%2077.5988%2034.9437L72.6684%2016.5432Z'/%3e%3c/mask%3e%3cpath%20d='M72.6684%2016.5432C83.5818%2013.619%2094.9937%2013.0584%20106.141%2014.8988C117.289%2016.7393%20127.915%2020.9384%20137.309%2027.2154C146.703%2033.4925%20154.649%2041.7027%20160.615%2051.2973C166.582%2060.8919%20170.431%2071.6497%20171.906%2082.8514C173.38%2094.0531%20172.447%20105.441%20169.167%20116.252C165.887%20127.064%20160.337%20137.051%20152.887%20145.546C145.438%20154.04%20136.261%20160.847%20125.969%20165.51C115.678%20170.173%20104.51%20172.585%2093.2117%20172.585L93.2117%20153.535C101.798%20153.535%20110.286%20151.702%20118.108%20148.158C125.929%20144.614%20132.904%20139.442%20138.565%20132.986C144.227%20126.53%20148.445%20118.94%20150.938%20110.723C153.43%20102.506%20154.14%2093.8512%20153.019%2085.3379C151.898%2076.8246%20148.973%2068.6487%20144.439%2061.3568C139.904%2054.0649%20133.865%2047.8251%20126.726%2043.0545C119.586%2038.284%20111.51%2035.0926%20103.038%2033.6939C94.566%2032.2952%2085.893%2032.7213%2077.5988%2034.9437L72.6684%2016.5432Z'%20fill='white'%20stroke='white'%20stroke-width='3.332'%20mask='url(%23path-4-inside-2_3690_24255)'/%3e%3cpath%20d='M93.6151%20114.251C99.6127%20114.251%20103.326%20111.466%20105.753%20107.039L108.966%20109.181C105.825%20114.893%20101.469%20118.106%2093.6151%20118.106C84.0475%20118.106%2077.4073%20111.609%2075.6223%2099.3281H71.2669V96.1151H75.2653C75.1939%2094.9013%2075.1225%2093.6875%2075.1225%2092.4023C75.1225%2091.1171%2075.1939%2089.9033%2075.2653%2088.6895H71.2669V85.4765H75.6223C77.3359%2073.1957%2084.0475%2066.6983%2093.6151%2066.6983C101.184%2066.6983%20105.825%2069.9827%20108.966%2075.4805L105.682%2077.6939C103.326%2073.4813%2099.3271%2070.5539%2093.6151%2070.5539C86.3323%2070.5539%2081.1201%2075.4805%2079.7635%2085.4765H97.3993L96.6853%2088.6895H79.4779C79.4065%2089.4749%2079.4065%2090.2603%2079.4065%2091.1171V93.6875C79.4065%2094.5443%2079.4065%2095.3297%2079.4779%2096.1151H95.0431L94.3291%2099.3281H79.7635C81.1201%20109.253%2086.3323%20114.251%2093.6151%20114.251Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_3690_24255'%3e%3crect%20width='185'%20height='185'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'/%3e%3cpath%20d='M93.0126%2099.9539C96.8448%2099.9539%2099.9515%2096.8472%2099.9515%2093.015C99.9515%2089.1827%2096.8448%2086.076%2093.0126%2086.076C89.1803%2086.076%2086.0737%2089.1827%2086.0737%2093.015C86.0737%2096.8472%2089.1803%2099.9539%2093.0126%2099.9539Z'%20fill='%230B1329'/%3e%3cpath%20d='M59.0911%2099.9539C62.9234%2099.9539%2066.03%2096.8472%2066.03%2093.015C66.03%2089.1827%2062.9234%2086.076%2059.0911%2086.076C55.2589%2086.076%2052.1522%2089.1827%2052.1522%2093.015C52.1522%2096.8472%2055.2589%2099.9539%2059.0911%2099.9539Z'%20fill='%230B1329'/%3e%3cpath%20d='M126.939%2099.9539C130.771%2099.9539%20133.878%2096.8472%20133.878%2093.015C133.878%2089.1827%20130.771%2086.076%20126.939%2086.076C123.107%2086.076%20120%2089.1827%20120%2093.015C120%2096.8472%20123.107%2099.9539%20126.939%2099.9539Z'%20fill='%230B1329'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_3690_24254'%20x1='93.018'%20y1='19'%20x2='93.018'%20y2='167.03'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2369FD90'/%3e%3cstop%20offset='1'%20stop-color='%23DFFAED'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)